|
| http://sourcecodemania.com/graph-implementation-in-cpp/ for details on implementation in C++. |
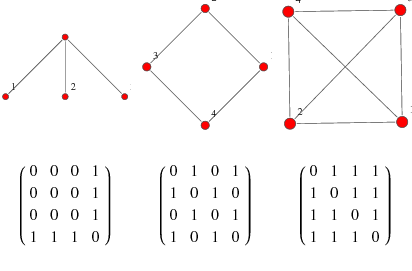
An issue that you man encounter when dealing with graphs sparsity. There are a lot of case where you create an adjacency matrix to hold your data and realize it is full of 0s. That can or cannot be useful depending on your application. Be for a more space efficient data structure use the Adjacency list (diagram above). The basic idea here is to create N x 1 array of linked lists. The elements in the linked list represent the connection the head node (node in graph) is connected to. Example from diagram above, Note that a is connected to d, b, c. Look up a in the array and note that a's linked list has all of its connections.